What should have been a relatively easy job turned into a very complex one. How I did battle with SQL Server and (mostly) won.
By the way, in case you're wondering about the title (and the subheading below if you've looked further on), then you obviously haven't read The Hunting Of The Snark by Lewis Carroll. If so, I strongly recommend you do, partly because it's a wonderful piece of sophisticated nonsense, and mainly because it's far more entertaining than this article! It was subtitled "An Agony In Eight Fits" with each section being described as a Fit. It seemed appropriate for what happened here...
Fit The First - Background
I had a request to allow the user to enter some keywords, and we would show all support tickets that used the keywords in any of a number of fields. As SQL Server provides a full-text search facility, this seemed ideal for the task. Little did I know how complex it would be! I'm documenting it here, in case anyone needs to do something like this again. Hopefully this will save them a few hours of pain.
Fit The Second - The database structure
In order to avoid mucking around with the database that was under source control, I created a test database, and created some tables that included only the relevant fields...
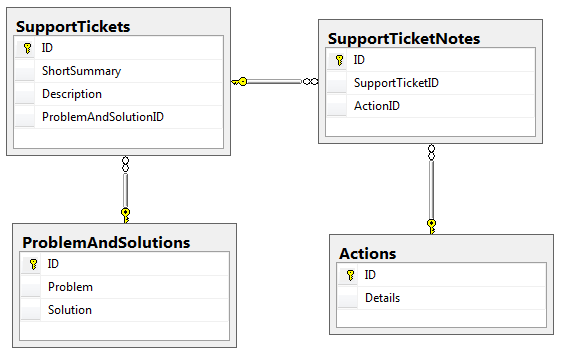
The main table is SupportTickets, which contains two fields to be indexed. Each ticket can have any number of SupportTicketNotes, and for various boring historical reasons, each of those has an associated Actions entry which contains the Details field that is to be included in the search. In addition, a ticket may have a ProblemsAndSolutions entry linked, in which case the two fields shown there are also to be included.
OK, all ready, I thought this would be a doddle. Ha, should have known better!
Fit The Third - Setting up the full-text catalogue
Creating full-text catalogues isn't too hard. You find the table you want to index, right-click it, and from the "Full-Text index" sub-menu, choose "Define Full-Text Index" (note the inconsistent capitalisation, naughty Microsoft!)...
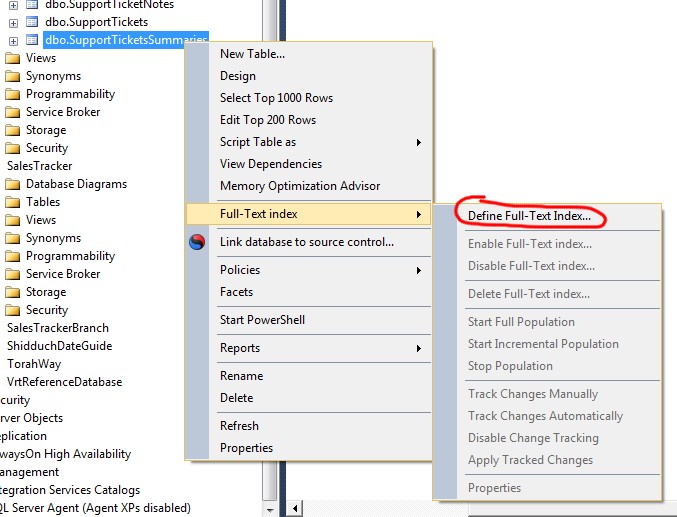
When the wizard appears, click past the first step (which just checks you have a primary key defined, and allows you to choose which to use), and you'll see the fields in the table...
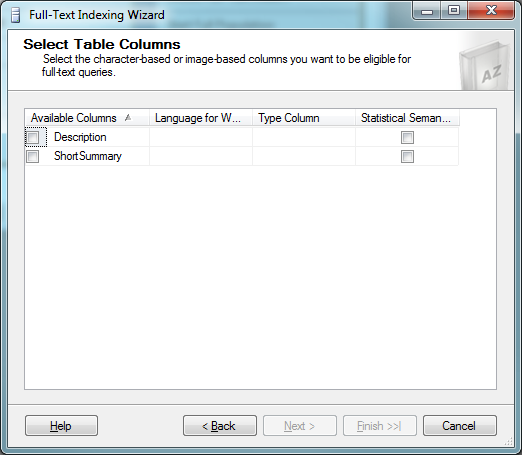
Check off the one(s) that you want to be indexed, and click Next. Click Next again to go past the change tracking step (you want to leave it as Automatically).
You now get to choose or create the full-text catalogue that will be used for the fields you chose. If this is the first time you've created a catalogue for this table, you'll want to check the "Create a new catalogue" checkbox and enter a name for the catalogue. I use the table name with FT appended, but I can't claim this is any standard.
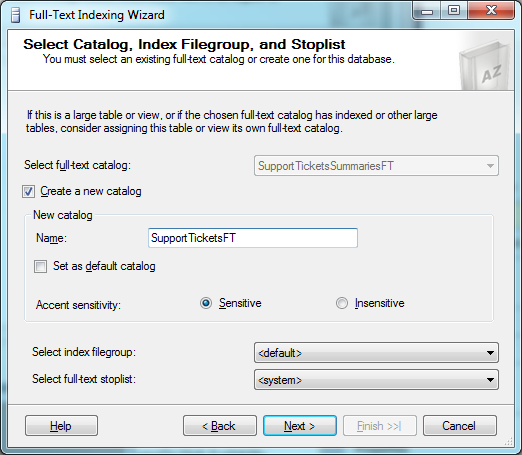
Make sure to click the Insensitive radio button. You can leave the two dropdowns at the bottom as they are and click Next.
Click Next again to go past the population schedules step as we don't need it.
You will then be shown a summary of the catalogue, and if you click Finish, it will be created and populated for you. Depending on how much data is in the table, it may take a few minutes for the catalogue to be fully populated.
So now we are ready to query the data...
Fit The Fourth - Single-table queries
There are various ways of querying full-text catalogues, and you can easily search to find out the benefits of each one. I used fulltexttable, as it has a very powerful algorithm for matching text, including variant word forms, proximity search, stop word ignoring, etc.
In order to search the data, you can use a query something like the following...
select ID, k.rank, ShortSummary, Description from SupportTickets st inner join freetexttable(SupportTickets, (ShortSummary, Description), 'computer') as k on st.ID=k.[key] order by rank desc
This uses freetexttable to create a full-text indexed view of the table, using the two columns we included in the catalogue. You can use any combination of indexed columns here, so you can query a subset of the fields if you wish. You can enter as many words as you like, and SQL Server will attempt to match as many as it can, taking frequency into account.
This gives results that look like this...
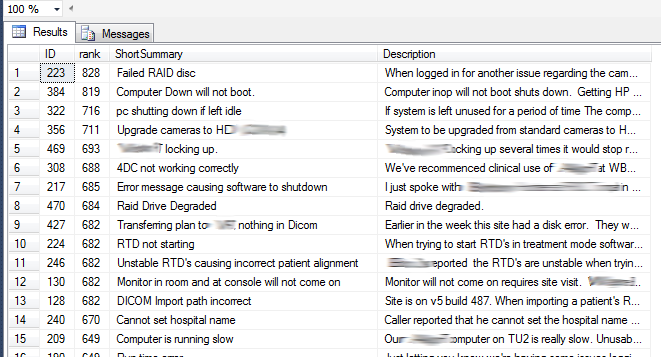
The first column is the ticket ID. The second column shows the rank, which is SQL Server's indication of how well the row matched the keyword(s) entered. Having searched around, I have come to the conclusion that the actual algorithm for calculating those ranks is based in some very deep Kabbalistic literature, and is partially based on how buckets of goat's entrails you've sacrificed to the Great God Of Database Servers that day. Microsoft seem to be pretty quiet on how the algorithm works, leaving us rather in the dark. This is a little embarrassing when you demo the feature to the client, and they, knowing their data a lot better that you, query for some significant keyword, and get the wrong results. You have to try and explain why your fab code, that you thought was working wonderfully well, came up with the wrong answers! Ho hum.
Note that as you can see from the query, we are selecting from the SupportTickets table, we can include any fields we like, not just those that were indexed.
If you only want to do full-text searching on one table, then you can skip down to Fit The Ninth, and avoid four fits of madness. Otherwise, take a deep breath and read on.
At this stage, I was smiling to myself, thinking that the job was nearly over. All I need to do is join the table,s and I'm done. Ha, teach me a lesson eh?
Fit The Fifth - Joining the tables
Armed with the above query, I set about writing one that would use all of the tables, and give me results that searched the tickets, their notes and the associated problems and solutions.
I'll spare you the gory details, but it turns out that you can't do this. Well, you can write some pretty scary queries that involve joining various freetexttables, but it doesn't work the way you expect, and you do your head in trying to work out how to combine the ranks.
So, off you go back to Google, Bing or whatever you use, and you find out that what you really need is a view...
Fit The Sixth - Creating a view for the query, and the discovery of stuff
Views are very useful in situations like this, as they enable you to write a complex query, wrap it in a view, and pretend it's a single table. They tend to be read-only, but that's not an issue here.
So, all I needed to do was write a query that joined the various tables, and wrap it in a view. simple eh?
Again, sparing you a few hours' worth of unpleasant details, the end result was that this wasn't so easy, as joining the tables resulted in multiple rows for each support ticket (ie one for each note). This made querying across all the fields impossible.
What I really needed was a way to pull all of the note information into one field, leaving me with one row per ticket, but with all of the note data present. If you've used the Linq Aggregate() method, you'll know what I mean.
After some searching, I came across the delightfully named stuff T-SQL keyword. When used in conjunction with its close friend xml, it enables you to do just what I described above. The syntax is a bit hairy at first, but it works...
select st.ID, st.ShortSummary, st.Description, isnull(ps.Problem, '') Problem,
isnull(ps.Solution, '') Solution,
(select isnull(stuff((select cast(Details as varchar(max)) + ' '
from SupportTicketNotes stn
inner join Actions a on a.ID=stn.ActionID
where stn.SupportTicketID=st.ID
for xml path('')), 1, 0, ''), '')) as Notes
from SupportTickets st
left join ProblemsAndSolutions ps on ps.ID=st.ProblemAndSolutionID
The first line of this is fairly simple, it's just selecting various fields. The second and third lines are where the clever stuff (sic) happens. I'm not going to give a full explanation of the stuff/xml syntax, partly because I don't fully understand it myself, and partly because it's dead dull and boring! If you're really interested, you can cure your insomnia by having a look at the MSDN pages about it. The query above is a little more complex than it needed to be, as the Details field of the Actions table was declared as type "text" which is incompatible with varchar, so I had to cast the one unto the other.
Anyway, the end result was the the data returned by this query included a Notes column that was an aggregation of all of the ticket's note details. I wrapped this query in a view, tested it out and was happy (briefly).
Ah, I must have cracked it this time. Well, no...
Fit The Seventh - Of unique keys, unique clustered indexes, schema binding and left joins
So there I was, ready to create a full-text catalogue on my shiny new view. You would think they would have the decency to leave me happy, but no, it all went wrong again.
When I tried to create the catalogue, I got an error message telling me it couldn't be created, as I needed a unique key on the view. Well, I thought I had one. After all, the primary table in the view is the SupportTickets table, and that has a unique key, which was included in the query, so what's the problem? The problem is that SQL Server is the boss, and it doesn't recognise that field as a unique key.
OK, so off to Google I went, and discovered that all you need to do is create a unique clustered index for the primary key, and away you go. Or not...
I tried the following fabulous piece of SQL...
create unique clustered index IX_SupportTicketsWithExtraInfo on SupportTicketsWithExtraInfo(ID)
...where SupportTicketsWithExtraInfo was the snappy name of my view. I was somewhat annoyed to be told that the index couldn't be created due to some weird error about schema binding. I can't remember the exact text, but it was something weird like that.
So back off to Google to find out what that was all about, and it seems that all you need to do is alter the view to include schema binding...
create view SupportTicketsWithExtraInfo with schemabinding as ...rest of the SQL here...
You know what's coming don't you. Another classic Microsoft "what the heck does that mean" error message...
Cannot schema bind view 'dbo.SupportTicketsWithExtraInfo' because name 'SupportTicketsWithExtraInfo is invalid for schema binding. Names must be in two-part format and an object cannot reference itself.Huh? It turns out that in order to use schema binding you have to use table names that consist of two parts, such as Furry.Ferrets and the like. Well, there was no way I was going to rename the tables, and having tried to use aliases and views to get around the problem, I realised that I wasn't going to be able to do it that way.
I don't remember the exact sequence of events at this point, as I think hysteria was setting in, but I eventually got to the stage where I had something that (theoretically at least) could be used in the full-text catalogue. Sadly, it wasn't to be.
The final insult in this sorry story was when I found out that you can't use full-text indexing on a view that uses a left or right join. No, I'm not making this up, honest!
I came across a forum post where someone tantalisingly mentioned a trick where you could simulate an inner join, which would have been just what I wanted, except that I couldn't find any hint of it anywhere.
So that was it. After all that, I was scuppered at the last stage. Back to the drawing board.
Note that if you want to create a full-text index on a view that doesn't include left or right joins, you will be OK, and can gleefully skip down to Fit The Ninth. As for me, I had to endure Fit The Eight first.
Fit The Eighth - The summary table and the triggers
At this point, I had to rethink the whole thing from the beginning. This was quite a strain on the brain cell, and involved a strong cup of herbal brew, but I eventually came up with the earth-shatteringly obvious idea of creating a new table to hold summaries of the support ticket information, and creating a full-text catalogue against that.
Remember stuff and xml from Fit The Sixth? Well that had enabled me to aggregate the note data into a single row in the view. All I needed to do was use this to aggregate the note data into the summary table. It was messy, but I ended up with triggers on the main tables that looked like this...
create trigger SupportTicketNotes_Update on SupportTicketNotes
after update
as
declare @ID int
select @ID = (select SupportTicketID from inserted)
declare @Notes varchar(max)
select @Notes = (select isnull(stuff((select cast(Details as varchar(max))
+ ' '
from SupportTicketNotes stn
inner join Actions a on a.ID=stn.ActionID
where stn.Active=1 and stn.SupportTicketID=@ID
for xml path('')), 1, 0, ''), ''))
update SupportTicketsSummaries set Notes=@Notes where ID=@ID
With similar triggers on the other tables, I ended up with a SupportTicketsSummaries table that contained the fields I needed, and was a plain old single table. Hurray, back to Fit The Fourth!
I created a full-text catalogue against the summary table, and was finally able to write a query that would query all the support ticket data...
select ID, k.rank,
ShortSummary + ' ' + Description + ' '
+ Problem + ' ' + Solution + ' ' + Notes Info
from SupportTicketsSummaries st
inner join freetexttable(SupportTicketsSummaries,
(ShortSummary, Description, Problem, Solution, Notes),
@SearchText) as k on st.ID=k.[key]
order by rank desc
I wrapped this up in a stored procedure, with a parameter for the search text, and breathed a sigh of relief. I'd done it, I was finally ready to import the stored procedure into the Entity Framework model, and get on with implementing the code.
You know what's coming don't you? You should by now.
Fit The Ninth - Trying to find the stored procedure
I went into Visual Studio, opened the .edmx file, right-clicked on the designer surface and chose "Update model from database" as I'd done so many times before. I opened the Stored Procedures section, and scrolled down to my fab new stored procedure... that wasn't there! Huh? Wh'appen?
Back to SSMS to double-check. No, it really is there. Try updating the model again, no joy.
It turns out that you have to grant EXEC permissions on the stored procedure before you can see it in the Entity Framework model. I checked the connection string to see which user was being used to access the database, and granted EXEC permissions.
Update (15th May '18): I have done something similar recently, and discovered that you don't seem to need to set EXEC permission on the stored procedure any more. not sure if this is because we upgraded from EF4 to EF6, or if I did something different, but I didn't grant the permission, and could see the stored procedure in the model.
However, I did discover another great issue, which is that if your stored procedure doesn't return any data (which my new one didn't), then although you can see it in the model, you can't actually access it! Ho hum. Another day, another agony.
After a few false starts, I managed to get past this hurdle, only to hit the next one...
Fit The Tenth - Where are my parameters?
One of the nice things about importing a stored procedure into Entity Framework is that the wizard will check what columns are returned, and either create or map a complex entity to match the results. Except it didn't. When I clicked the button to get the schema, I got the grammatically awful message €œThe selected stored procedure or function returns no columns.€ I know they are American, but they could make some effort to write decent English! I know, it's probably decent American, but I wasn't in a mood to argue to the point at this stage!
After a lot of searching, I didn't get very far. I found a lot of people reporting the same problem, but they were all using dynamic SQL or temporary tables. I wasn't using either, so didn't get any benefit from the suggestions.
I never did find an answer to this bit. I wondered if maybe the freetexttable was seen as a temporary table, or maybe it actually is a temporary table. I couldn't find an answer, but I did come across a wonderfully simple way around it.
The facility to detect the schema and generate a complex entity is a nice extra, but you don't actually have to use it. All you need to do is open the Model Browser, right-click on the Complex Types node, and add a new complex type that has properties that match the columns returned by your stored procedure. Make sure the names match the columns returned by your stored procedure exactly.
Then start the function import wizard, choose complex type, and pick the one you just created from the drop-down list.
Fit The Eleventh - Using the new function in the code
This bit turned out to be surprisingly easy, once I had remembered to regenerate the entities. The following code was all that was needed to get the results of the full-text search...
List<SupportTicketsFullTextSearchResults> rankedIDs = context.SupportTicketsSearch(searchText).ToList();
Armed with this, I was able to pull out the full tickets for those in this query, and deliver them in ranked order.
As a final touch, I normalised the ranks, so that the highest one was always 100, and the others decreased, then used this to give the user an indication of the relative relevance of each ticket...
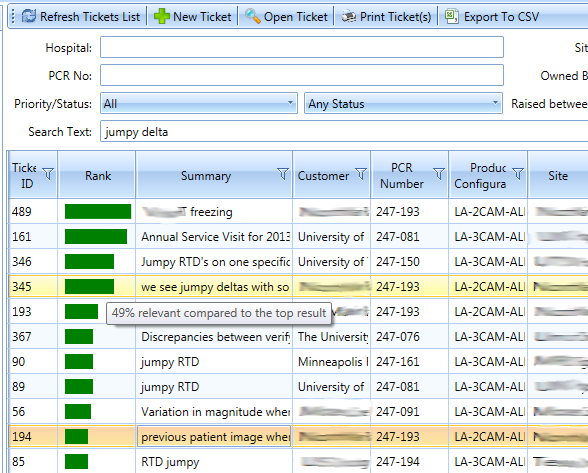
I showed this to the client, and got a heart-warming enthusiastic response. Made it all worthwhile.
Well, almost!
Comments
No approved comments yet.